
DSPy
DSPy is an open-source Python framework for programming language models with typed signatures, composable modules, metrics, and optimizers instead of brittle prompt strings. It is best for teams building reliable LLM pipelines, RAG systems, classifiers, extraction workflows, and agents that need measurable improvement over time.
DSPy is a strong fit for developers and AI teams that want evaluation-driven LLM programs instead of hand-maintained prompt chains. It is less suitable for users who want a hosted AI app builder, AI IDE, or no-code agent product.
Pricing Plans
Open Source
DSPy is free to install and use as a Python package under the MIT license.
Model Provider Costs
Inference, embeddings, retrieval, and fine-tuning costs depend on the configured model provider, API usage, and infrastructure.
Self-Managed Production
Teams are responsible for hosting, monitoring, evaluation data, secrets, caching, model endpoints, and deployment operations.
Core Features
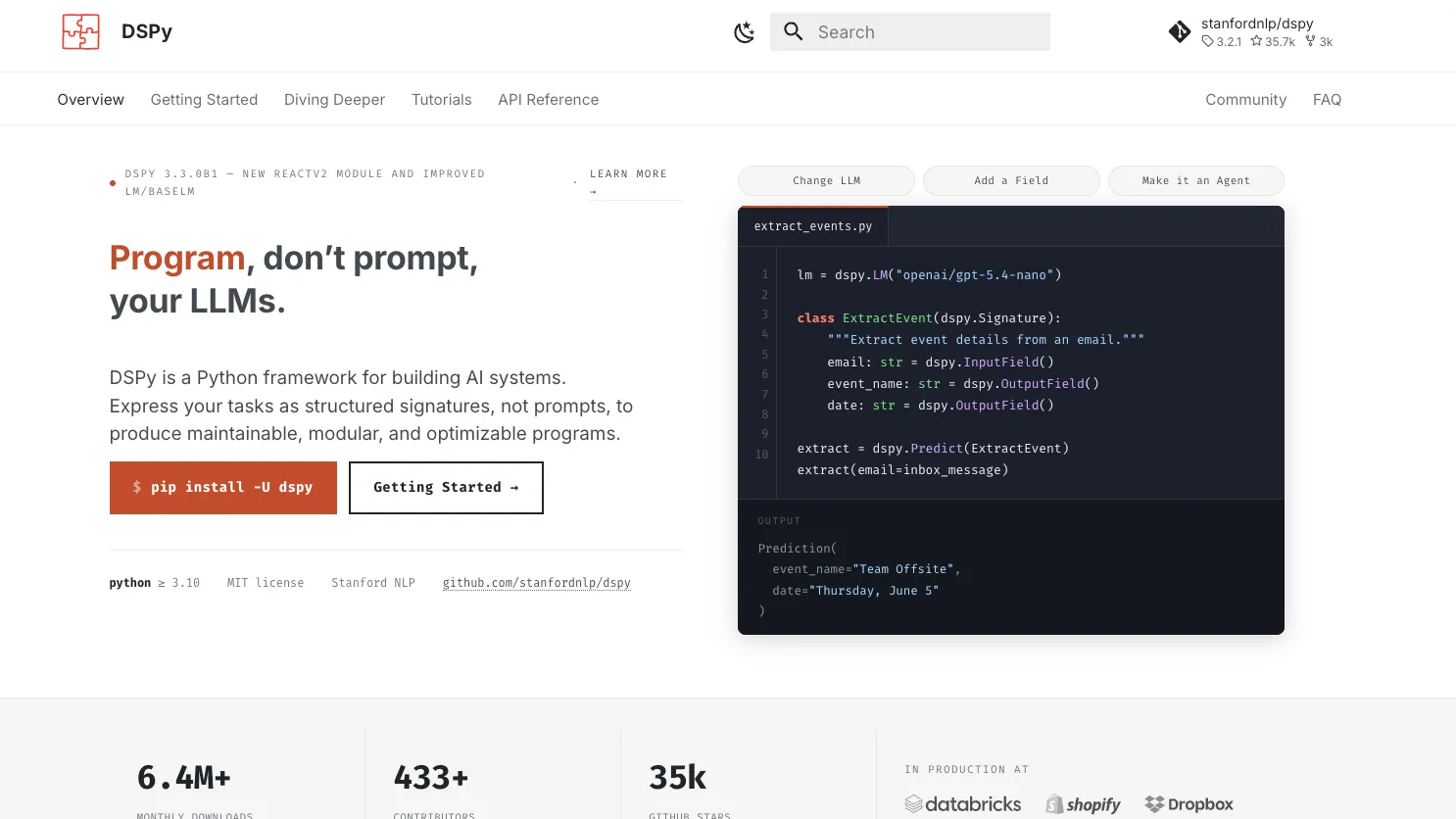
1Programming Model
- Typed signatures for declaring input and output behavior
- Composable modules such as Predict, ChainOfThought, and ReAct
- Python-first pipelines instead of hard-coded prompt templates
- Reusable program components for extraction, classification, RAG, and agents
2Optimization and Evaluation
- Optimizers compile programs against metrics and examples
- Prompt and demonstration optimization for multi-stage LM programs
- Support for custom scoring functions and training examples
- Save and reload optimized programs
3Model and Provider Flexibility
- Configured through dspy.LM with provider model strings
- Uses LiteLLM behind the scenes for broad provider compatibility
- Supports provider switching without rewriting module logic
- Can be used with API-based or compatible local/self-hosted model endpoints
4Agents and Tools
- ReAct-style tool-using modules
- Plain Python functions can be exposed as tools
- Useful for retrieval, search, computation, and multi-step workflows
- Supports modular agent loops with inspectable intermediate steps
5Developer Workflow
- Install with pip install dspy
- Python 3.10+ package
- MIT-licensed GitHub project
- Works inside normal Python projects, notebooks, services, and experiments
Pros
- Replaces fragile prompt strings with structured, testable Python programs.
- Strong fit for RAG, extraction, classification, multi-step reasoning, and agent workflows.
- Optimizers make prompt and demonstration tuning more systematic than manual prompt engineering.
- Model-provider flexibility helps teams switch LLMs without rewriting the whole application.
- Open-source MIT license and active research-backed ecosystem.
- Good for teams that care about evaluation metrics, reproducibility, and measurable quality improvement.
Cons
- Not an AI IDE, visual app builder, or no-code agent platform.
- Requires Python skills and a stronger ML/evaluation mindset than simple prompt chaining.
- Optimization workflows need examples, metrics, and disciplined evaluation data.
- Production reliability depends on the surrounding app, model provider, retrieval layer, and observability stack.
- The abstraction can feel heavy for one-off prompts or very simple chatbot prototypes.
- Teams still need to manage secrets, cost, caching, tracing, deployment, and model governance.
Why Choose DSPy?
DSPy is useful when prompt engineering starts to become software engineering. A single prompt can be managed manually, but a production LLM system often has multiple steps, retrieval calls, classifiers, extraction tasks, ranking logic, tool calls, and evaluation requirements.
DSPy addresses that problem by treating language model behavior as a program. Instead of writing long prompt strings by hand, developers define structured inputs and outputs, compose modules, define metrics, and let optimizers improve the program against examples.
The main benefit is not that DSPy makes LLM apps easier for beginners. Its benefit is that it makes serious LLM systems more systematic. Teams that care about reliability, regression testing, model switching, cost reduction, and measurable quality gains will get more value from DSPy than teams building one-off chatbot demos.
Core Workflow
A practical DSPy workflow begins by defining what each language-model step should do. This usually starts with a signature: the typed contract for inputs and outputs. The developer then chooses a module such as direct prediction, chain-of-thought reasoning, retrieval-augmented generation, or ReAct-style tool use.
The next step is evaluation. DSPy becomes more powerful when the team defines examples and a metric that captures useful behavior. That metric may be exact match, semantic similarity, answer faithfulness, extraction accuracy, classification F1, human preference alignment, or a custom scoring function.
Once the program, examples, and metric exist, an optimizer can compile a better version of the program. This can improve instructions, demonstrations, or multi-stage behavior without manually rewriting every prompt.
A simplified workflow looks like this:
- Define the task contract with a signature.
- Select or compose modules for the reasoning strategy.
- Add retrievers, tools, or external functions when needed.
- Create examples and a scoring metric.
- Run an optimizer against the program.
- Save the optimized program.
- Compare quality, latency, and cost across models.
- Deploy the program inside a normal Python application.
This is a different mindset from prompt chaining. DSPy encourages developers to ask: what should be measured, optimized, swapped, and reused?
Use Cases
DSPy is strongest for tasks where quality can be measured. That includes RAG systems, question answering, classification, extraction, routing, summarization pipelines, support triage, tool-using agents, and multi-hop reasoning workflows.
For RAG, DSPy is useful because retrieval, answer generation, citation behavior, and faithfulness can be represented as separate parts of a program. Instead of tuning a single prompt by intuition, teams can optimize the full pipeline against examples and metrics.
For extraction and classification, DSPy is helpful because structured signatures make the expected output explicit. This can reduce the fragility of natural-language-only prompts and make it easier to compare models or reasoning strategies.
For agents, DSPy is most useful when the agent has bounded tools and measurable success criteria. It is less appropriate for open-ended autonomous systems with unclear objectives and no evaluation set.
Comparison to Alternatives
LangChain is the most common comparison. LangChain provides broad building blocks for agents, chains, tools, integrations, and application orchestration. DSPy is narrower and more opinionated around programming language-model behavior and optimizing it against metrics. Choose LangChain when integration breadth and orchestration patterns matter most. Choose DSPy when prompt and pipeline optimization is the center of the problem.
LlamaIndex is the strongest comparison for RAG-heavy applications. LlamaIndex focuses deeply on data ingestion, indexing, retrieval, and knowledge workflows. DSPy can be better when the team wants to optimize the reasoning and generation program around retrieval. Many teams may combine both: LlamaIndex for data and retrieval infrastructure, DSPy for structured language-model programs and optimization.
Haystack is another practical comparison for search and QA systems. It is often a better fit for production search pipelines, retrievers, readers, and enterprise information retrieval workflows. DSPy is more compelling when the main challenge is optimizing language-model calls and multi-step prompt behavior.
Semantic Kernel is relevant for teams in Microsoft-heavy environments or those building planner/tool-based AI applications. DSPy is less enterprise-framework oriented but stronger as a research-backed optimization layer for LLM programs.
Instructor and Guidance are closer comparisons for structured outputs and controlled generation. They are usually simpler to adopt for schema-constrained outputs. DSPy is heavier, but it gives teams a broader framework for composing and optimizing multi-stage programs.
Best Configuration
DSPy works best when teams treat evaluation data as a first-class asset. Before optimizing anything, the team should define representative examples, failure cases, and a metric that reflects the real product goal.
For RAG systems, that means collecting questions, expected answers, relevant documents, and faithfulness checks. For extraction, it means labeled examples and schema-level validation. For classification, it means class definitions, edge cases, and class imbalance awareness.
A strong production setup usually includes:
- a small development set for fast iteration,
- a separate validation set for optimizer decisions,
- a held-out test set for regression checks,
- cached model calls to control cost,
- versioned optimized programs,
- provider-specific latency and cost tracking,
- and explicit rules for when a model or optimizer change can ship.
DSPy should also be paired with normal software practices. The program should live in source control, evaluation should run in CI where practical, and optimized artifacts should be versioned like application code.
Migration Notes
Migrating from hand-written prompts to DSPy should be incremental. The best first target is usually a painful prompt that has clear inputs, outputs, and evaluation data. Rewriting an entire agent or RAG system at once can make it difficult to understand whether DSPy improved the system or simply changed too many variables.
A practical migration path is:
- Pick one prompt-heavy step with measurable output.
- Convert it into a DSPy signature and module.
- Add 20 to 100 representative examples if available.
- Define a metric that catches the real failure mode.
- Compare the hand-written prompt against the DSPy program.
- Optimize only after the baseline is working.
- Save the optimized program and track changes over time.
Teams moving from LangChain or LlamaIndex do not need to replace everything. DSPy can often sit inside those systems as the optimized language-model layer. For example, retrieval can remain in LlamaIndex while answer generation, reranking, or claim verification is implemented as DSPy modules.
Practical Evaluation Checklist
Before adopting DSPy, teams should validate the following:
- Does the project have repeatable language-model tasks rather than one-off prompts?
- Can the team define useful input and output contracts?
- Are there examples or logs that can become an evaluation set?
- Is there a metric that reflects quality beyond subjective preference?
- Will model switching, cost reduction, or prompt optimization create real value?
- Can the engineering team maintain Python code and deployment infrastructure?
- Are prompts, outputs, traces, and cached data safe to store or inspect?
- Does the team understand which parts of the pipeline are optimized and which are fixed?
If these conditions are present, DSPy can make LLM development more systematic. If the team only needs a quick chatbot, a simpler framework or hosted builder may be the better starting point.
Best For
- RAG pipelines
- LLM-powered extraction systems
- Text classification workflows
- Question answering systems
- Multi-step language model programs
- Agent loops with tools
- Prompt and demonstration optimization
- Evaluation-driven LLM application development
- Teams comparing models across the same program interface
- Research-to-production LLM prototyping
Not Ideal For
- Developers looking for an AI code editor
- Teams that need a terminal coding agent
- Non-technical users looking for a no-code app builder
- Simple one-off prompt experiments
- Visual workflow automation without Python
- Hosted enterprise LLM application management out of the box
- Teams without evaluation examples or quality metrics
Privacy Notes
DSPy is a local Python framework and does not provide a hosted application runtime by itself. Data exposure depends on the configured language model provider, retriever, vector database, logging, caching, telemetry, notebooks, and deployment environment. Teams should review API keys, prompt and output logs, optimizer training examples, cached traces, retrieval documents, and provider data-retention policies before using sensitive data.
Alternatives
Sources
Update History
- Jul 2, 2026: Classified DSPy as a developer-workflow framework rather than an AI IDE, CLI coding agent, or prompt-to-app builder.
- Jul 2, 2026: Verified current official positioning around structured signatures, modules, optimizers, Python 3.10+, MIT license, and LiteLLM-based provider flexibility.
Related Tools
More listings in a similar part of the directory.






DSPy Articles
Guides, comparisons, and launch notes connected to this listing.


