文章2026年6月23日2
Codex 升级后还在狂写 TRACE?一次真实检测暴露 AI 编程工具的新风险
~/.codex/logs_2.sqlite 仍然可能在活跃/流式响应期间大量写入 TRACE 日志。最近围绕 OpenAI Codex 的一个讨论在开发者圈传播开来:
Codex 在流式任务和长时间运行时,可能会以较高频率写入
~/.codex/logs_2.sqlite,导致本地 SSD 写入量异常。
这个说法听起来很吓人,甚至有人把它称为“Codex 史诗级大 BUG”。
但从技术角度看,这件事不能简单归类为“AI 工具会写爆硬盘”。更准确的描述应该是:
Codex 在部分版本和部分使用场景下,会把大量 TRACE 级别日志持久化写入本地 SQLite 数据库;在高强度、长时间、流式响应频繁的场景中,这可能造成不必要的磁盘写入压力。
这里的关键词有三个:
logs_2.sqlite-wal 文件。问题不是模型本身“偷偷训练”,也不是 Codex 在下载巨量数据。
真正的问题是:本地日志系统可能过于吵闹。
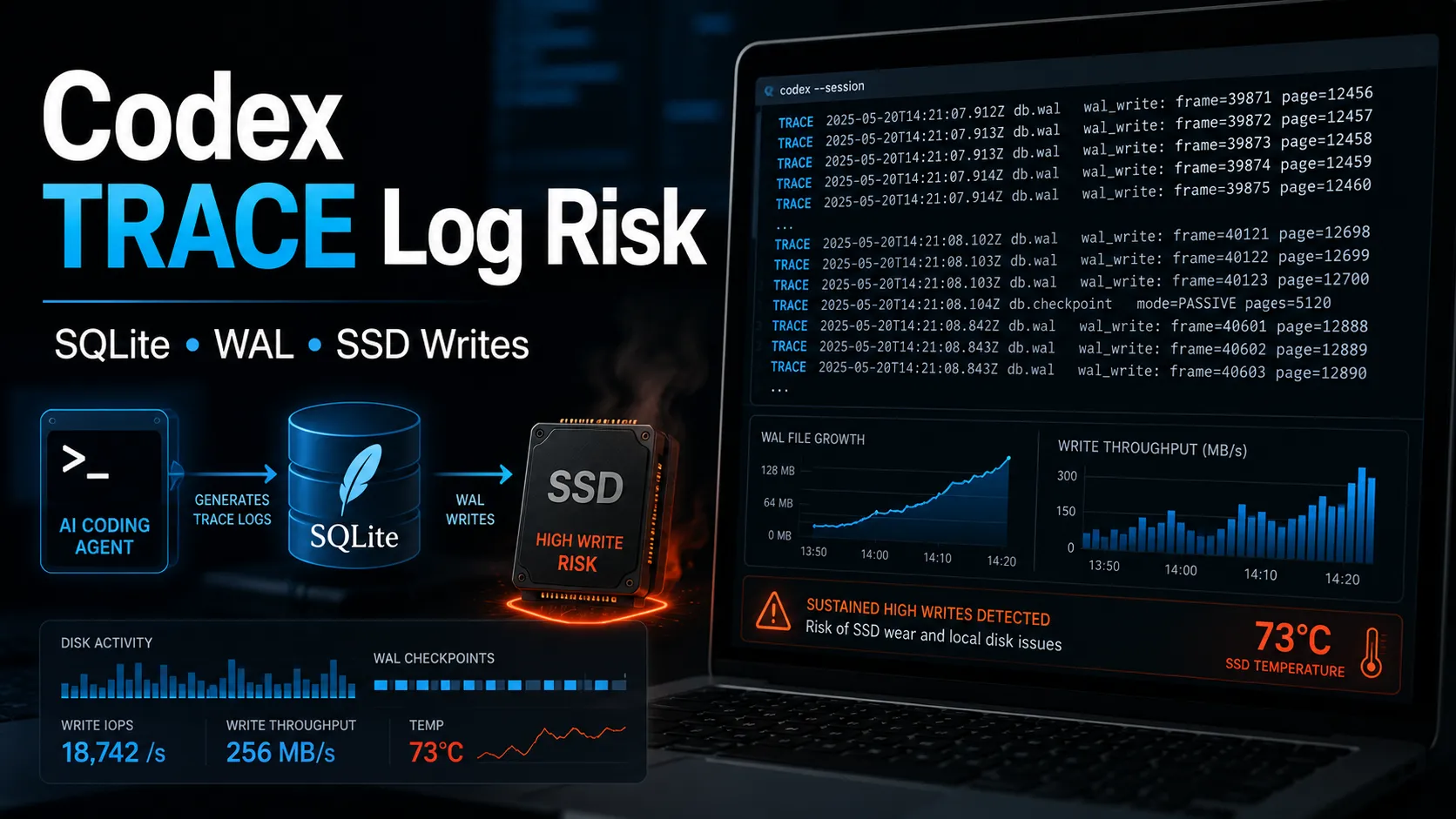
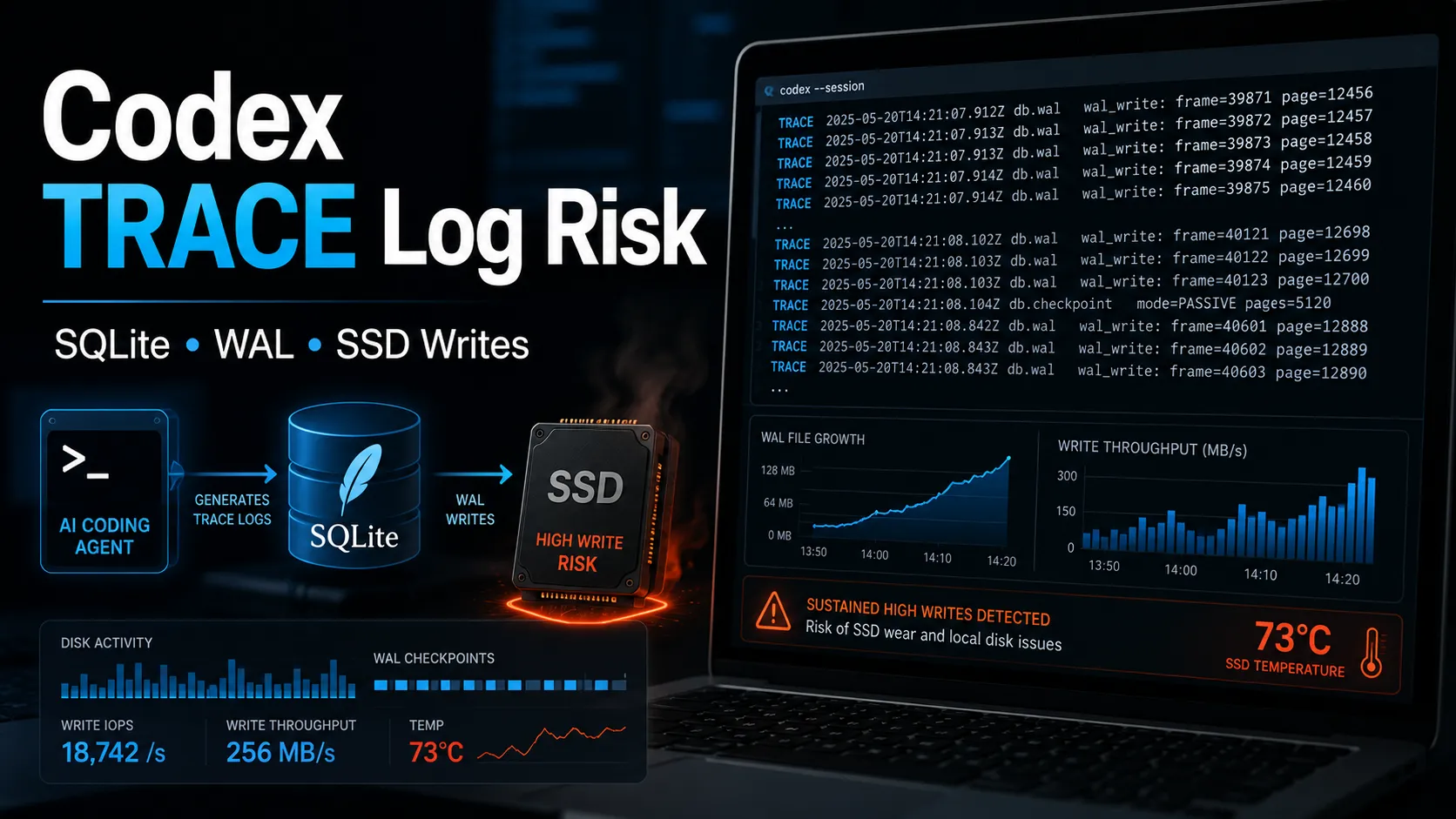
基于实际只读检测,升级后的 Codex 仍然出现了明显的 TRACE 日志写入。
检测过程没有执行备份、trigger、checkpoint、truncate,也没有修改 ~/.codex/logs_2.sqlite,只读取了文件体积、日志级别分布、表结构、MAX(id) 和 WAL 文件状态。
关键结果如下:
text logs_2.sqlite:约 186 MB logs_2.sqlite-wal:约 13.5 MB 当前保留日志:约 74,178 行 总体 TRACE:50,730 行,约 68.4% 最近 5000 条里 TRACE:3,932 条,约 78.6% 20 秒采样里 MAX(id):79,654,866 → 79,655,068,增加 202 最近一分钟 TRACE:1,885 条 WAL 大小:采样期间维持约 13.5 MB,未继续膨胀
最近日志 target 中仍然出现了多类流式链路相关模块:
text codex_api::sse::responses codex_api::endpoint::responses_websocket codex_app_server::outgoing_message codex_tui::markdown_stream
这些数据说明:
升级后,Codex 在活跃响应期间仍然存在较高频率的 TRACE 日志写入。
但同时也要注意另一个事实:
WAL 文件并没有在这次采样中持续膨胀。
这意味着当前更适合被判断为“异常写盘风险”,而不是“已经进入 SSD 灾难状态”。
判断这类问题,不能只看一条指标。
MAX(id) 增长,说明日志插入仍在发生。
TRACE 占比高,说明日志级别确实偏吵。
但 WAL 没有持续变大,说明还没有观察到最危险的无界膨胀。
因此,实际结论应该分层:
MAX(id) 在 20 秒内继续增长。RUST_LOG、CODEX_LOG、OTEL_LOG_LEVEL。所以最准确的判断是:
Codex 升级后仍然存在活跃任务期间 TRACE 日志高频写入问题;目前属于值得处理的本地 I/O 风险,但还不是“立即写废 SSD”的确定性结论。
很多用户看到“官方修复已合并”后,会自然以为只要升级就完全没事。
但现实往往更复杂。
Codex 可能存在多个分发渠道:
不同渠道的更新时间可能不同。
所以“已经升级”并不等于“已经包含最新修复”。
更可靠的做法是确认实际运行版本:
bash codex --version which codex
如果是在 VS Code、Cursor 或其他 IDE 中使用,还应该检查插件版本,以及插件内部调用的是哪个 Codex 二进制或服务。
从问题性质看,合理修复通常不会完全删除所有日志。
因为日志对排查问题仍然有价值。
更可能的修复方向是:
这类修复能显著减少写入,但不一定让 MAX(id) 完全停止增长。
因此,升级后仍然看到一些日志写入,并不奇怪。
真正要看的是:
AI 编程助手和传统 CLI 工具不一样。
它不是执行一次命令就退出。
它可能持续处理:
如果日志系统把这些事件全部记录下来,就很容易产生高频写入。
这也是为什么这类问题更容易出现在 Codex、Claude Code、Cursor、Windsurf 这类“agentic coding tool”上,而不是传统代码补全插件上。
建议先做只读检测,不要一上来就改数据库。
以下命令只读取文件和数据库,不会写入或清理:
`bash DB="$HOME/.codex/logs_2.sqlite" WAL="$DB-wal"
ls -lh "$DB" "$WAL" 2>/dev/null sqlite3 -readonly "$DB" "SELECT level, COUNT() FROM logs GROUP BY level ORDER BY COUNT() DESC;" sqlite3 -readonly "$DB" "SELECT MAX(id), COUNT(*) FROM logs;" `
如果想观察是否还在增长,可以做多次采样:
`bash DB="$HOME/.codex/logs_2.sqlite" WAL="$DB-wal"
for i in 1 2 3; do date '+%F %T' sqlite3 -readonly "$DB" "SELECT MAX(id), COUNT(*) FROM logs;" ls -lh "$WAL" 2>/dev/null sleep 10 done `
如果想看最近日志里 TRACE 占比:
`bash DB="$HOME/.codex/logs_2.sqlite"
sqlite3 -readonly "$DB" " SELECT level, COUNT() FROM ( SELECT level FROM logs ORDER BY id DESC LIMIT 5000 ) GROUP BY level ORDER BY COUNT() DESC; " `
如果想看最近 target 来源:
`bash DB="$HOME/.codex/logs_2.sqlite"
sqlite3 -readonly "$DB" " SELECT level, target, COUNT() FROM ( SELECT level, target FROM logs ORDER BY id DESC LIMIT 5000 ) GROUP BY level, target ORDER BY COUNT() DESC LIMIT 20; " `
如果最近 5000 条日志里 TRACE 占比超过 50%,就值得关注。
如果超过 70%,说明日志级别明显偏吵。
实际检测中,最近 5000 条 TRACE 占比约 78.6%,这已经不是正常的用户级日志密度。
MAX(id) 代表日志插入序列。
如果 Codex 活跃时增长,可以理解。
如果 Codex 空闲几分钟后仍然快速增长,就更危险。
建议分别做两次测试:
如果空闲状态也持续增长,风险等级需要上调。
logs_2.sqlite-wal 是观察风险的重要指标。
如果 WAL 长期维持在十几 MB,风险较低。
如果 WAL 快速涨到几百 MB、几 GB,甚至几十 GB,就需要立即处理。
实际检测中,WAL 约 13.5 MB,采样期间未继续变大。
这说明当前还没有进入最危险状态。
真正影响 SSD 和电脑体验的,不只是 SQLite 文件大小,而是系统实际写入量。
需要关注:
如果这些现象和 Codex 活跃时间高度重合,问题就不仅是“日志文件看起来大”,而是实质性资源占用。
先确认当前真正运行的是哪个 Codex:
bash codex --version which codex
如果存在多个安装源,例如 npm、Homebrew、IDE 插件同时安装,要特别小心。
常见坑包括:
不要只在 Codex 正在回答时判断。
建议让 Codex 停止任务,空闲 2 到 3 分钟,再采样:
`bash DB="$HOME/.codex/logs_2.sqlite" WAL="$DB-wal"
for i in 1 2 3 4; do date '+%F %T' sqlite3 -readonly "$DB" "SELECT MAX(id), COUNT(*) FROM logs;" ls -lh "$DB" "$WAL" 2>/dev/null sleep 20 done `
判断方式:
MAX(id) 基本不涨:主要是活跃流式任务期间集中写入。MAX(id) 继续快速增长:更严重,说明后台也在持续写。虽然实际检测中没有发现显式 TRACE 环境变量,但其他用户仍然应该检查:
bash env | grep -Ei 'RUST_LOG|CODEX_LOG|OTEL_LOG_LEVEL|LOG_LEVEL|TRACE'
重点关注:
text RUST_LOG CODEX_LOG OTEL_LOG_LEVEL LOG_LEVEL
如果这些变量被设置为 trace,应优先取消或降级到 info / warn。
建议策略是:
Codex 这类工具迭代非常快,升级不只是为了新功能,更是为了拿到本地 I/O、日志、权限、稳定性方面的修复。
在确认问题完全修复前,高强度用户可以采取这些保守策略:
~/.codex 目录大小。这不是根治,但可以降低持续写入时间窗口。
社区流传的紧急处理方式大致是:
logs_2.sqlite、logs_2.sqlite-wal、logs_2.sqlite-shm。logs 表插入。PRAGMA wal_checkpoint(TRUNCATE);。MAX(id) 和 WAL 不再增长。从技术上看,这个方案可以止血。
但它不是第一选择。
原因很简单:这属于修改 Codex 内部数据库结构。
可能带来的副作用包括:
如果一定要使用,建议优先考虑只拦截 TRACE,而不是拦截所有日志。
示例:
sql CREATE TRIGGER IF NOT EXISTS block_trace_logs BEFORE INSERT ON logs WHEN NEW.level = 'TRACE' BEGIN SELECT RAISE(IGNORE); END;
如果拦截所有日志:
sql CREATE TRIGGER IF NOT EXISTS block_all_logs BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE); END;
但 block_all_logs 更激进,会让 Codex 基本失去本地日志能力。
更合理的触发条件是:
MAX(id) 仍持续增长。在这些条件出现前,更建议先保持只读监控。
特征:
logs_2.sqlite 小于 200 MB。MAX(id) 不增长。建议:
特征:
MAX(id) 快速增长。建议:
实际检测数据更接近这个等级。
特征:
建议:
因为 Codex 这件事反映了一个更大的变化:
AI 编程工具正在从“插件”变成“本地开发基础设施”。
传统代码补全插件主要做建议。
而新一代 AI coding agent 会做更多事情:
这意味着它们的资源占用也会更接近一个长期运行的开发服务,而不是一个轻量插件。
过去开发者会定期升级浏览器,因为浏览器关系到安全和兼容性。
后来开发者会维护 Docker、Node、Python、数据库,因为它们关系到项目稳定性。
现在,Codex、Cursor、Claude Code、Windsurf 这类 AI 编程工具也进入了同一个维护范畴。
它们不应该“装完就忘”。
不一定。
SQLite + WAL + insert/delete + checkpoint 可能造成实际写入量高于文件表面大小。
判断风险不能只看数据库文件大小,还要看:
MAX(id) 增长速度。不一定。
需要确认:
不一定。
trigger 是拦截写入,不是修复 Codex 本身的日志策略。
它更像“堵住出口”,不是“解决源头”。
不一定。
TRACE 的确不应该在普通场景大量持久化,但完全砍掉日志也会牺牲诊断能力。
更稳的方式是:
~/.codex 目录大小。~/.codex 日志大小纳入异常排查 checklist。Codex 这类问题也给所有 AI 工具开发者一个提醒:
Codex 的 TRACE 日志高频写盘问题,不能被简单解读为“AI 工具会写废 SSD”。
更准确的结论是:
在实际检测中,升级后的 Codex 仍然可能在活跃/流式响应期间大量写入本地 SQLite TRACE 日志;这属于真实存在的本地 I/O 风险,但是否严重取决于 WAL 是否持续膨胀、空闲状态是否继续写入,以及系统层面是否出现异常磁盘写入。
当前最稳妥的处理方式不是恐慌卸载,也不是立刻改数据库结构。
更合理的路径是:
最重要的一点是:
AI 编程工具已经成为开发者的新基础设施,不能再按“普通插件”的方式长期放着不管。
如果正在高强度使用 Codex,建议立即做一次只读检测,并把 Codex 加入定期升级清单。
升级不是为了追新功能,而是为了拿到性能、日志、权限和稳定性修复。
更多围绕相同主题、协议或工具的文章。
浏览与本文主题相关的目录条目。